

Introduction
Dans le domaine de la data science, le partage et le déploiement de modèles de machine learning sont des aspects cruciaux. Cet article vise à vous guider à travers le processus d’exportation d’un modèle au format Pickle et son intégration dans une application Streamlit. L’objectif est de créer une solution interactive pour partager les résultats des modèles avec un public plus large.
Étape 1 : Entraînement du Modèle
Commencez par entraîner un modèle de machine learning de votre choix. Pour cet exemple, supposons un modèle de classification des fleurs utilisant Scikit-Learn. Pour cela je vous conseille de crée un Jupyter Notebook afin d’entrainer votre modèle.
import pandas as pd
import json
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv"
df = pd.read_csv(url)
# affichage des modalités de species
print(df.species.mode())
#encodage de la colonne species
df["species_encoded"] = pd.factorize(df.species)[0]
# split des données pour l'entrainement
y = df.species_encoded
df = df.drop(['species', 'species_encoded'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2, random_state=42)
# entrainement du modèle random forest classifier
model = RandomForestClassifier(n_estimators=10, random_state=42, max_depth=2)
model.fit(X_train, y_train)Langage du code : Python (python)0 setosa
1 versicolor
2 virginica
Name: species, dtype: objectLangage du code : Bash (bash)Étape 2 : Exporter le Modèle avec Pickle
Utilisez la bibliothèque Pickle pour sauvegarder le modèle entraîné dans un fichier. L’avantage c’est que grâce à cela vous ne serez pas obligé de ré-entrainer votre modèle dans le streamlit 😌
import pickle
# Sauvegarder le modèle dans un fichier
with open('modele.pkl', 'wb') as fichier_modele:
pickle.dump(model, fichier_modele)Langage du code : Python (python)Étape 3 : Exporter les dépendances
Afin de s’affranchir d’une réutilisation du code utilisé dans le Notebook lors de l’entrainement, il est commun d’exporter les informations que l’on souhaite afficher dans notre application Streamlit. Pour cela nous avons besoin d’exporter le nom et les valeurs Min et Max de nos caractéristiques, ainsi que l’équivalence de notre cible encodée et le nom de la classe de fleur.
Pour cela rien de plus simple, json est le format idéal pour faire cela. Commençons par les caractéristiques :
# Calculer les statistiques descriptives
description = df.describe()
# Obtenir les valeurs min et max de chaque feature
min_max_dict = {
feature: {'min': description.at['min', feature], 'max': description.at['max', feature]}
for feature in description.columns
}
# Enregistrer dans un fichier JSON
with open('feature_min_max.json', 'w') as json_file:
json.dump(min_max_dict, json_file, indent=4)Langage du code : PHP (php)Toujours en utilisant la méthode dump il est possible de stocker le dictionnaire python contenant les informations qui nous intéressent. Observons le fichier feature_min_max.json :
{
"sepal_length": {
"min": 4.3,
"max": 7.9
},
"sepal_width": {
"min": 2.0,
"max": 4.4
},
"petal_length": {
"min": 1.0,
"max": 6.9
},
"petal_width": {
"min": 0.1,
"max": 2.5
}
}Langage du code : JSON / JSON avec commentaires (json)On retrouve bien toutes les informations des caractéristiques utilisées pour entrainer notre modèle. C’est-à-dire le nom, la valeur Min et Max. Ces données nous serviront comme dépendances pour notre application Streamlit.
Maintenant, faisons la même chose pour notre cible :
# Encoder la target
df = pd.read_csv(url)
encoded_target, unique_values = pd.factorize(df['species'])
# Créer un mapping de l'encodage
target_mapping = {index: value for index, value in enumerate(unique_values)}
# Enregistrer le mapping dans un fichier JSON
with open('target_encoding.json', 'w') as json_file:
json.dump(target_mapping, json_file, indent=4)Langage du code : PHP (php)Observons également le fichier target_encoding.json :
{
"0": "setosa",
"1": "versicolor",
"2": "virginica"
}Langage du code : JSON / JSON avec commentaires (json)Remarque : exporter l’équivalence classe : catégorie, est utile pour les modèles de classification. Pour les modèles de régression il n’est pas nécessaire de créer le fichier target_encoding.json
Maintenant nous avons tout ce qu’il faut pour créer notre application Streamlit sans avoir besoin du dataset afin de crée une prédiction 🤓. Ci-dessous un schéma qui résume ce qu’on vient de faire :
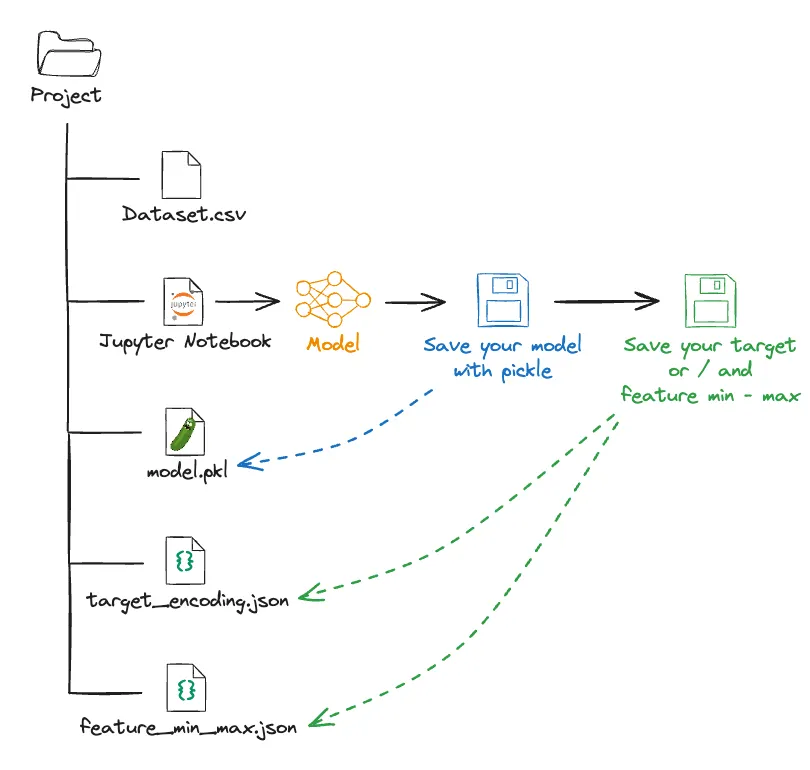
Étape 4: Créer une Application Streamlit
Streamlit simplifie la création d’application web interactives en Python. Installez Streamlit avec la commande pip install streamlit et créez un fichier Python pour l’application Streamlit.
Ce fichier Python aura bien évidemment besoin des dépendances que l’on a crée auparavant. Pour cela je vous conseille de placer votre fichier Python contenant votre code dans le même répertoire ou se trouve votre modèle au format .pkl et .json.
Maintenant passons au code de notre application à l’aide de Streamlit :
# Importer les bibliothèques nécessaires
import streamlit as st
import pickle
import json
import numpy as np
def charger_modele():
# Charger le modèle à partir du fichier Pickle
with open('modele.pkl', 'rb') as fichier_modele:
modele = pickle.load(fichier_modele)
return modele
def charger_min_max():
# Charger les valeurs min et max des caractéristiques depuis le fichier JSON
with open('feature_min_max.json', 'r') as json_file:
min_max_dict = json.load(json_file)
return min_max_dict
def charger_target_mapping():
# Charger le mapping des targets depuis le fichier JSON
with open('target_encoding.json', 'r') as json_file:
target_mapping = json.load(json_file)
# Convertir les clés en entiers
target_mapping = {int(key): value for key, value in target_mapping.items()}
return target_mapping
# Charger les valeurs min et max
min_max_dict = charger_min_max()
# Interface utilisateur Streamlit
st.title("Application de Classification des espèces de fleurs")
# Créer des curseurs pour chaque caractéristique en utilisant les noms et valeurs depuis le JSON
caracteristiques_entree = []
for feature, limits in min_max_dict.items():
caracteristique = st.slider(
f"{feature}",
float(limits['min']),
float(limits['max']),
float((limits['min'] + limits['max']) / 2)
)
caracteristiques_entree.append(caracteristique)
# Charger le modèle et le mapping de la cible
modele = charger_modele()
target_mapping = charger_target_mapping()
# Préparer les caractéristiques pour la prédiction
caracteristiques = np.array([caracteristiques_entree])
# Prévoir la classe avec le modèle
prediction_encoded = modele.predict(caracteristiques)
# Décoder la prédiction
prediction_decoded = target_mapping[prediction_encoded[0]]
# Afficher la prédiction
st.markdown(
f"<p style='font-size:24px; font-weight:bold;'>La prédiction de l'espèce est : {prediction_decoded}</p>",
unsafe_allow_html=True
)
Langage du code : Python (python)Comme vous pouvez le voir ici, nous avons importé le strict nécessaire, aucune librairie de sciki-learn, et uniquement les librairies nous permettant de charger nos dépendances. Ainsi notre fichier python utilise le fichier contenant notre modèle au format pickle, et les deux fichiers json.
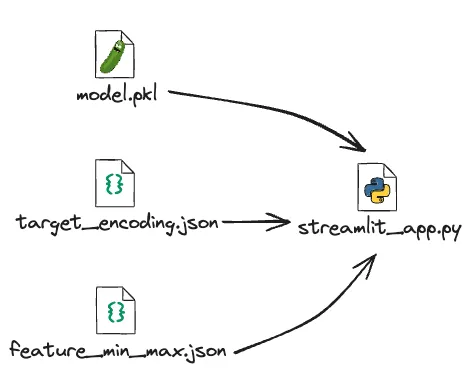
Étape 5: Exécution de l’Application
Lors de l’exécution de l’application Streamlit, assurez-vous que le nombre de caractéristiques utilisées par le modèle est respecté. Si le modèle attend quatre caractéristiques en entrée, ajustez les widgets dans l’interface utilisateur en conséquence.
streamlit run streamlit_app.pyLangage du code : Bash (bash)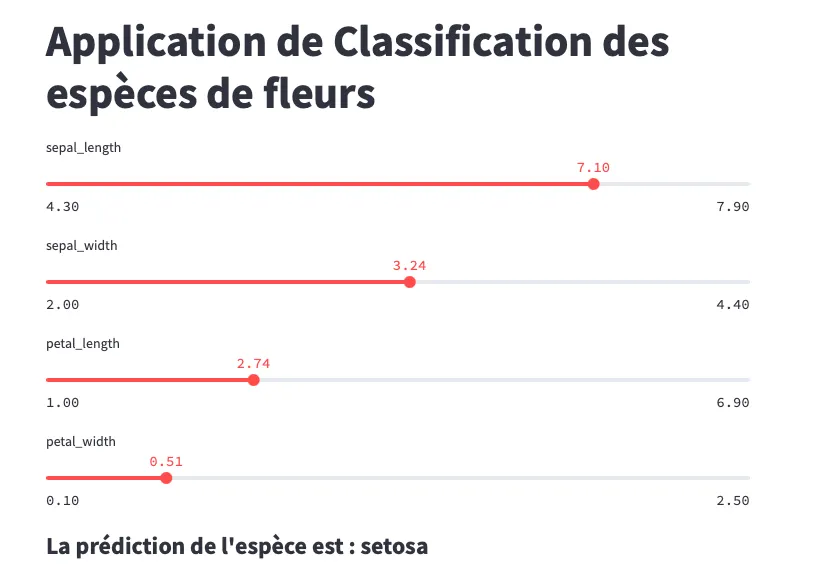
Conclusion
Félicitations, vous avez maintenant appris à exporter un modèle de machine learning au format Pickle et à l’intégrer dans une application Streamlit. Assurez-vous simplement de respecter le même nombre de caractéristiques lors de la création de l’interface utilisateur pour garantir des prédictions précises et fiables. N’oubliez pas d’utiliser @st.cache dans le reste de votre application afin d’améliorer les performances en évitant le rechargement constant du modèle ou de vos données, rendant ainsi l’expérience utilisateur plus fluide.