

Dans le monde de la programmation, la création de jeux de données réalistes est souvent une nécessité. Faker est une bibliothèque Python qui permet de générer des données factices de manière simple et efficace. Dans cet article, nous explorerons les différentes fonctionnalités de Faker, son installation, les méthodes les plus utilisées, et nous verrons comment créer un jeu de données réaliste dans un DataFrame.
Présentation de Faker
Faker est une bibliothèque open-source en Python qui fournit des outils pour générer des données aléatoires de différentes catégories telles que les noms, adresses, numéros de téléphone, adresses e-mail, dates, textes, etc. Ces données fictives sont créées de manière à sembler réelles, ce qui les rend idéales pour créer des jeux de données de test, des prototypes d’applications ou pour effectuer des démonstrations. Faker est largement utilisé dans le développement de logiciels, le data mining, les tests automatisés, et bien d’autres domaines.
Pour commencer à utiliser Faker, vous devez l’installer dans votre environnement Python. Vous pouvez le faire en utilisant pip, le gestionnaire de paquets de Python. Voici la commande à exécuter dans votre terminal :
pip install fakerLangage du code : Bash (bash)Une fois installée, vous pouvez importer la bibliothèque Faker dans votre code Python en utilisant l’instruction suivante :
from faker import Faker Langage du code : Bash (bash)Faker propose de nombreuses méthodes pour générer des données dans différentes catégories. En voici quelques-unes des plus couramment utilisées :
- Génération de noms : name(), first_name(), last_name()
- Génération d’adresses : address(), city(), country()
- Génération de numéros de téléphone : phone_number(), cell_phone()
- Génération d’adresses e-mail : email()
- Génération de dates : date_of_birth(), date_time_between()
- Génération de textes : sentence(), paragraph()
Ces méthodes peuvent être utilisées individuellement pour générer des valeurs aléatoires ou combinées pour créer des jeux de données plus complexes et réalistes.
Cas d’utilisation pour créer un jeu de données dans un DataFrame
L’un des cas d’utilisation les plus courants de Faker est la création de jeux de données dans un DataFrame, une structure de données tabulaire utilisée dans la manipulation et l’analyse de données. Pour cela, nous aurons besoin de la bibliothèque pandas en plus de Faker.
Voici un exemple de code qui génère un jeu de données aléatoire comprenant des noms, des adresses et des numéros de téléphone, le tout stocké dans un DataFrame :
import pandas as pd
from faker import Faker
fake = Faker('fr_FR')
data = []
for _ in range(5):
name = fake.name()
job = fake.job()
address = fake.address()
phone = fake.phone_number()
data.append((name, job, address, phone))
df = pd.DataFrame(data, columns=['name', 'job', 'address', 'phone'])
df.head()
Langage du code : Python (python)
Par défaut la langue utilisé par Faker est l’anglais, mais il est tout à fait possible d’utiliser d’autre langue. je vous met aussi quelque exemples avec du Français, Anglais, Japonais, Russe, Italien, Portugais, Chinois et Allemand etc.
locales = ['fr_FR', 'en_US', 'es_ES', 'ja_JP', 'ru_RU', 'it_IT', 'pt_PT', 'zh_CN', 'de_DE']
fake = Faker(locales)
# Génération des données dans le DataFrame
data = []
for locale in locales:
fake = Faker(locale)
for _ in range(1):
name = fake.name()
job = fake.job()
address = fake.address()
phone = fake.phone_number()
data.append((name, job, address, phone, locale))
# Création du DataFrame
df = pd.DataFrame(data, columns=['name', 'job', 'address', 'phone', 'country'])
df.head(9)
Langage du code : Python (python)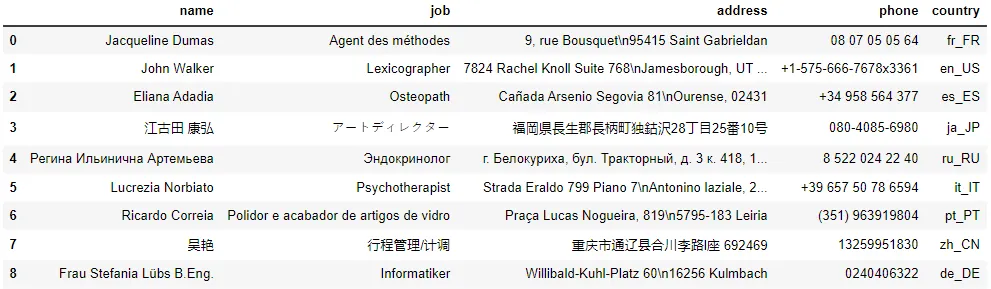
La méthode profile vous permettra de faire la même chose mais avec beaucoup plus d’information comme par exemple une date de naissance, le sexe, etc.
data = [fake.profile() for _ in range(5)]
df = pd.DataFrame(data)
df.head()
Langage du code : Python (python)
Avec toutes ces méthodes vous serez en mesure de créer un jeu de données réalistes pour vous constituer une base de données et entrainer vos algorithmes ou autres.
Pour aller plus loin, dans le prochain article je vous partagerais comment anonymiser un jeu de données à l’aide de Faker. Stay tuned !