
Dans un précédent article je vous ai présenté comment générer un dataframe contenant des fausses données de personne afin de vous constituer un jeu de données pour vos tests. Cependant, lorsqu’on travaille sur des pipelines de données on est souvent contraint d’utiliser un format de fichier bien défini. Eh oui tout n’est pas dataframe.
Prenons l’exemple d’une pipeline qui a besoin de traiter des fichiers XML contenant des données à caractère personnel, et vous avez besoin de faire des tests pour valider votre pipeline. C’est assez délicat d’utiliser ces données. Je vous propose donc une méthodologie afin d’anonymiser des fichiers XML.
Pseudonymiser ou anonymiser ?
La pseudonymisation consiste à remplacer les informations identifiantes par des pseudonymes (par exemple, remplacer le nom d’une personne par un identifiant unique). Cependant, un lien de correspondance est conservé dans un autre fichier ou système, ce qui permet, si nécessaire, de rétablir l’identité réelle de la personne. Autrement dit, la pseudonymisation est réversible.
L’anonymisation, au contraire, vise à supprimer toute possibilité d’identification d’une personne, même indirecte. Une fois les données anonymisées, il devient impossible de retrouver l’identité de l’individu concerné, car aucun lien ne subsiste entre les données et la personne.
Ces deux notions sont donc fondamentalement différentes : la pseudonymisation protège temporairement l’identité, tandis que l’anonymisation la rend définitivement indétectable.
Le besoin
Essayons de faire quelque chose de simple et surtout réutilisable. J’ai un fichier XML contenant des données à caractère personnel et je souhaite avoir un script Python capable de modifier les noms, prénom et email. Pour que notre outil soit paramétrable, nous allons répertorier les balises XML à modifier dans un fichier YAML.

Fichier XML exemple
Je vous propose le fichier XML ci-dessous contenant plusieurs balises. Ce qu’il faut retenir c’est que ce type de fichier est encore beaucoup utilisé dans le monde de la data et souvent pour échanger des données entre différents logiciels ou contenue dans des bases de données. Il existe des librairies Python capable de lire des fichiers XML, toutefois nous n’allons pas nous attarder sur cette librairie aujourd’hui.
<?xml version="1.0"?>
<Catalog>
<Book id="bk101">
<Author>Garghentini, Davide</Author>
<first_name>John</first_name>
<last_name>Doe</last_name>
<email>JohnDoe@notme.org</email>
<Title>XML Developer's Guide</Title>
<Genre>Computer</Genre>
<Price>44.95</Price>
<PublishDate>2000-10-01</PublishDate>
<Description>An in-depth look at creating applications
with XML.</Description>
</Book>
<Book id="bk102">
<Author>Garcia, Debra</Author>
<Title>Midnight Rain</Title>
<Genre>Fantasy</Genre>
<Price>5.95</Price>
<PublishDate>2000-12-16</PublishDate>
<Description>A former architect battles corporate zombies,
an evil sorceress, and her own childhood to become queen
of the world.</Description>
</Book>
</Catalog>Langage du code : HTML, XML (xml)Nos fonctions de chargement et conversion
Commençons par faire une fonction capable de charger les balises à modifier contenue dans un fichier YAML ainsi que le fichier XML :
def anonymize_xml(xml_file, yaml_file):
# Charger le fichier YAML contenant les balises à anonymiser et les textes à générer
with open(yaml_file, 'r') as f:
yaml_data = yaml.safe_load(f)
# Charger le fichier XML
tree = ET.parse(xml_file)
root = tree.getroot()
Langage du code : Python (python)Maintenant qu’on à chargé nos deux fichiers rentrons dans le cœur du sujet. La prochaine fonction doit être capable de modifier un texte avec un élément de Faker
def randomize_text(text, faker):
if text.startswith('faker.'):
faker_method = getattr(faker, text.split('faker.')[1])
return faker_method()
else:
return text
Langage du code : Python (python)Et voilà une bonne chose de faite. Pour votre information, parcourir un fichier XML nécessite de respecter une arborescence bien définie. Je ne vais pas m’attarder là-dessus ici aujourd’hui. Afin de parcourir les données dans le fichier XML je vais utiliser la librairie ElementTree.
Passons maintenant au code final
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import xml.etree.ElementTree as ET
import yaml
from datetime import datetime
from faker import Faker
def randomize_text(text, faker):
if text.startswith('faker.'):
faker_method = getattr(faker, text.split('faker.')[1])
return faker_method()
else:
return text
def anonymize_xml(xml_file, yaml_file):
# Charger le fichier YAML contenant les balises à anonymiser et les textes à générer
with open(yaml_file, 'r') as f:
yaml_data = yaml.safe_load(f)
# Charger le fichier XML
tree = ET.parse(xml_file)
root = tree.getroot()
# Initialiser Faker
faker = Faker()
# Parcourir les éléments du fichier XML
for element in root.iter():
# Vérifier si l'élément doit être anonymisé
if element.tag in yaml_data:
text = yaml_data[element.tag] # Récupérer le texte à générer depuis le fichier YAML
element.text = randomize_text(text, faker) # Générer la valeur aléatoire avec Faker
# Créer un nom de fichier avec l'horodatage
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
output_file = f"anonymized_{timestamp}.xml"
# Enregistrer les modifications dans le fichier XML
tree.write(output_file, encoding="utf-8", xml_declaration=True)
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Usage: python script.py <xml_file> <yaml_file>")
sys.exit(1)
xml_file = sys.argv[1]
yaml_file = sys.argv[2]
anonymize_xml(xml_file, yaml_file)
Langage du code : Python (python)Le fichier YAML
Maintenant que le script est prêt, il faut définir quelle vont être les balises à modifier. Pour cela on va se créer un fichier YAML contenant les balises à modifier et spécifier les méthodes faker à utiliser pour chaque balise. Disons que dans notre exemple de fichier XML, je souhaite modifier les balises suivantes : Author, first_name, last_name et email. Donc cela devrait nous donner le fichier de configuration YAML suivant :
Author: faker.name # Remplacer par un nom complet aléatoire
first_name: faker.first_name # Remplacer par un prénom aléatoire
last_name: faker.last_name # Remplacer par un nom de famille aléatoire
email: faker.email # Remplacer par une adresse e-mail aléatoire
Langage du code : YAML (yaml)Exécution du script
Maintenant que l’on a notre script, le fichier de configuration YAML et le fichier XML à anonymiser, on va enfin pouvoir essayer ça et comparée. Pour l’exécuter, rien de plus simple, depuis une console il faut donner au script les bons arguments :
xmlAnonym.py data4test.xml balises.yamlLangage du code : Bash (bash)Conclusion
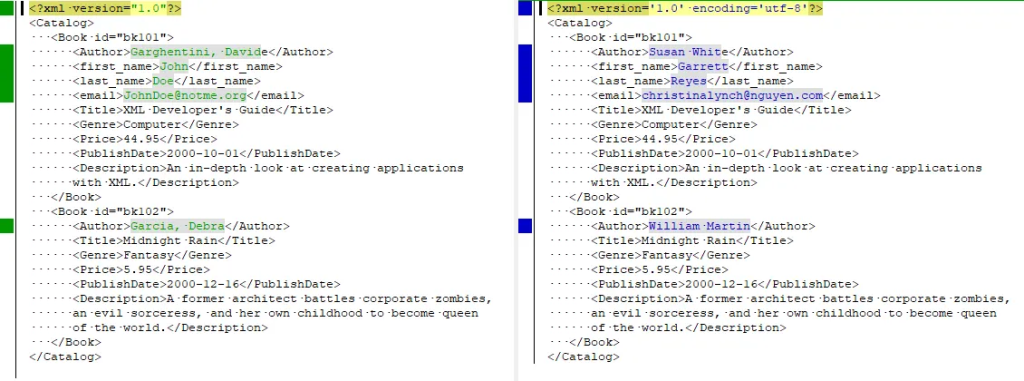
Enfin maintenant si on compare les deux fichiers, l’original et celui anonymisé grâce à notre script, on observe bien que les champs Author, first_name, last_name et email ont été modifiés.
Bien entendue vous pouvez utiliser le script pour plusieurs fichiers XML afin de vous constituer des jeux de données et travailler sur vos pipelines de données tout en respectant les règles RGPD.